We present a novel domain adaptation framework that uses morphologic segmentation to translate images from arbitrary input domains (real and synthetic) into a uniform output domain. Our framework is based on an established image-to-image translation pipeline that allows us to first transform the input image into a generalized representation that encodes morphology and semantics - the edge-plus-segmentation map (EPS) - which is then transformed into an output domain. Images transformed into the output domain are photo-realistic and free of artifacts that are commonly present across different real (e.g. lens flare, motion blur, etc.) and synthetic (e.g. unrealistic textures, simplified geometry, etc.) data sets. Our goal is to establish a preprocessing step that unifies data from multiple sources into a common representation that facilitates training downstream tasks in computer vision. This way, neural networks for existing tasks can be trained on a larger variety of training data, while they are also less affected by overfitting to specific data sets. We showcase the effectiveness of our approach by qualitatively and quantitatively evaluating our method on four data sets of simulated and real data of urban scenes.
Paper
In: Autonomous Driving: Perception, Prediction and Planning (ADP3) at IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2021
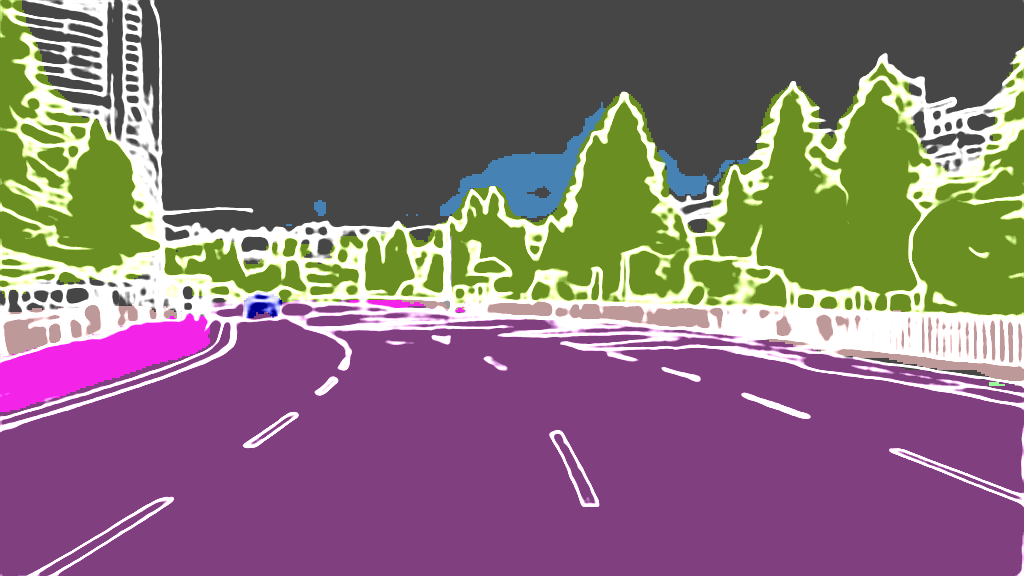
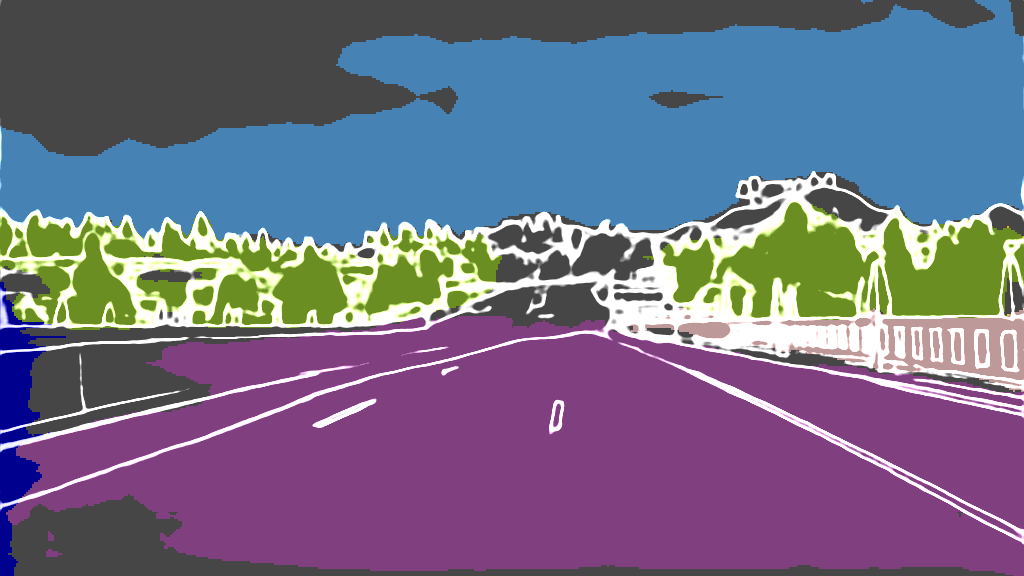
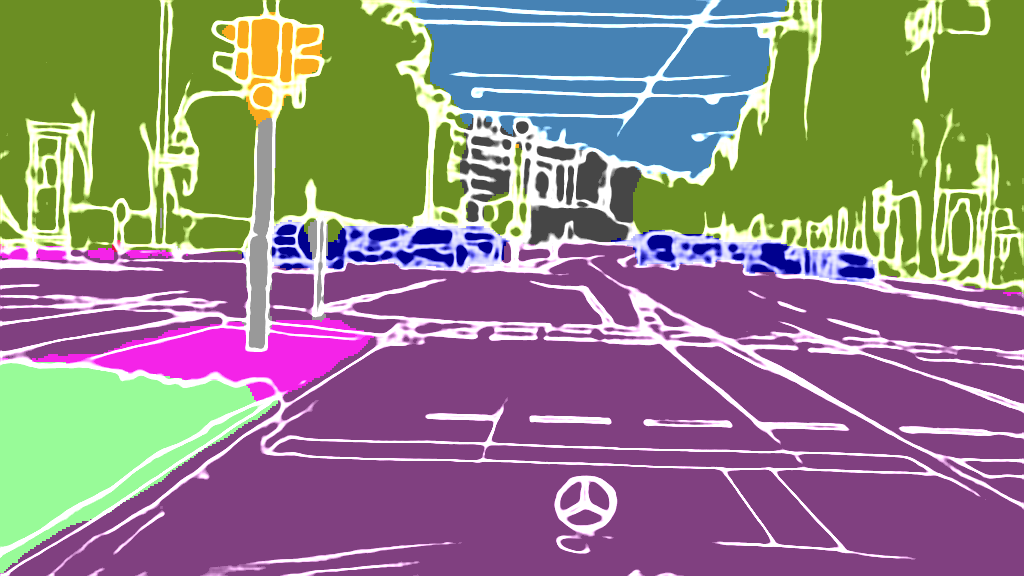
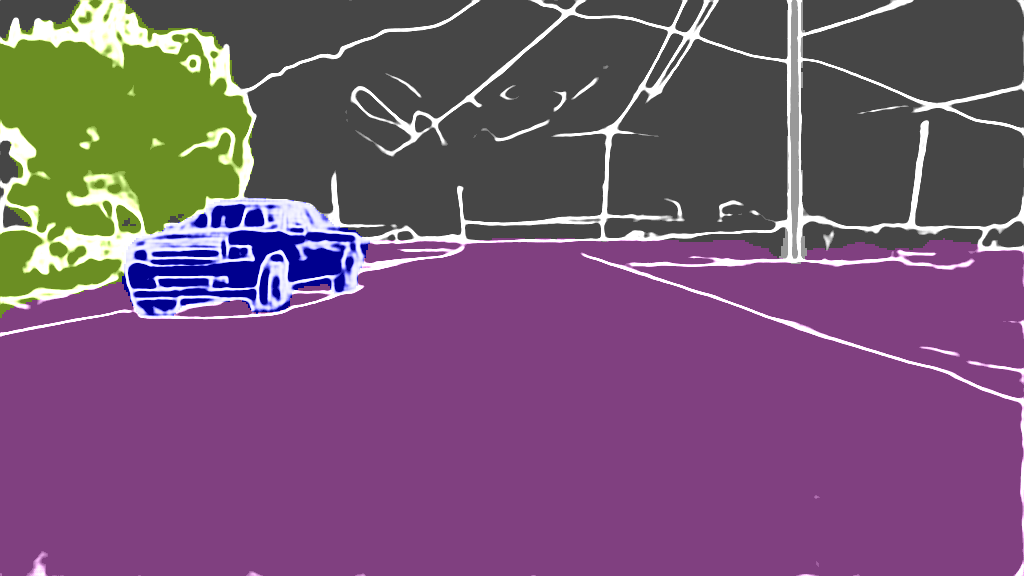
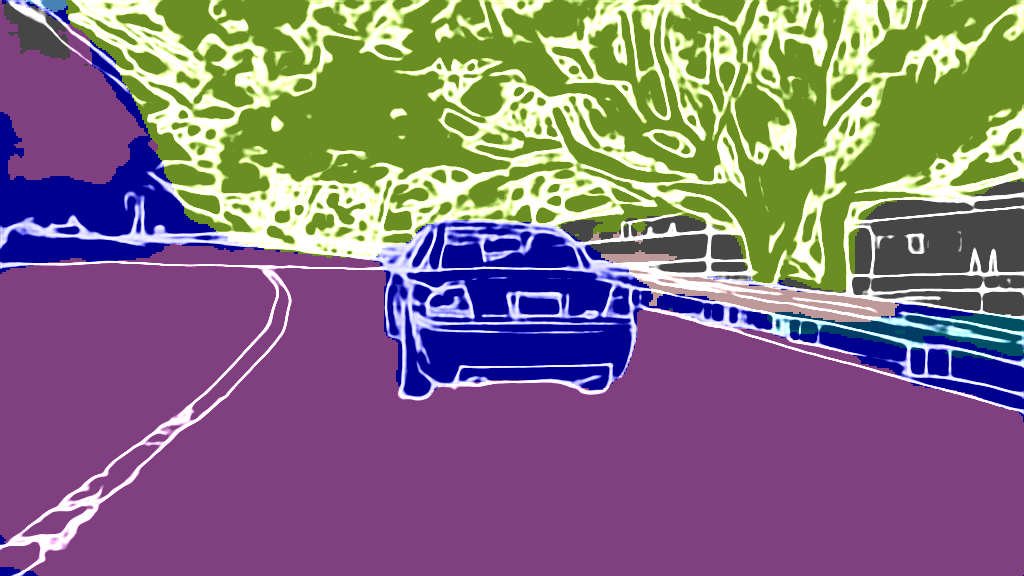
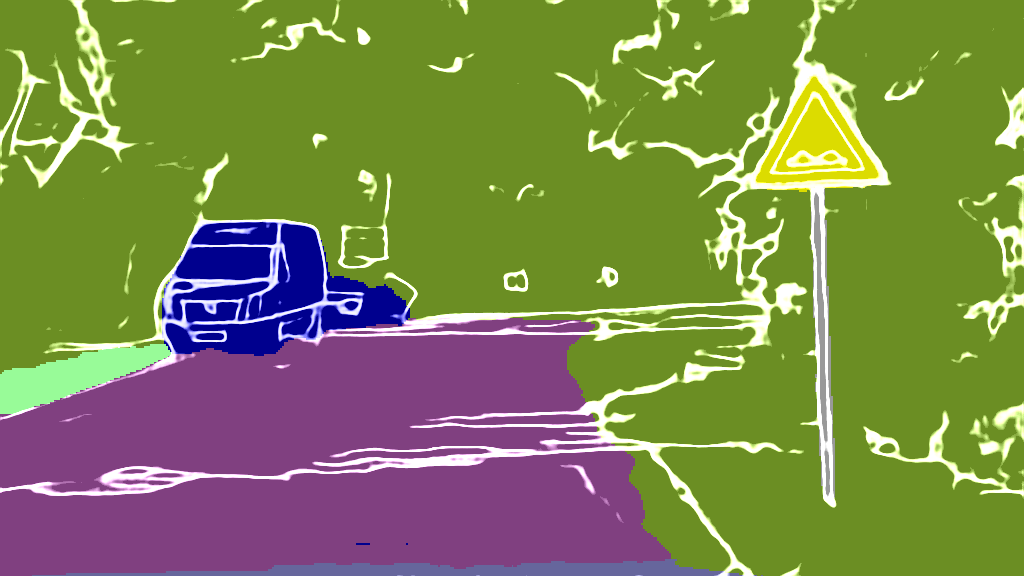
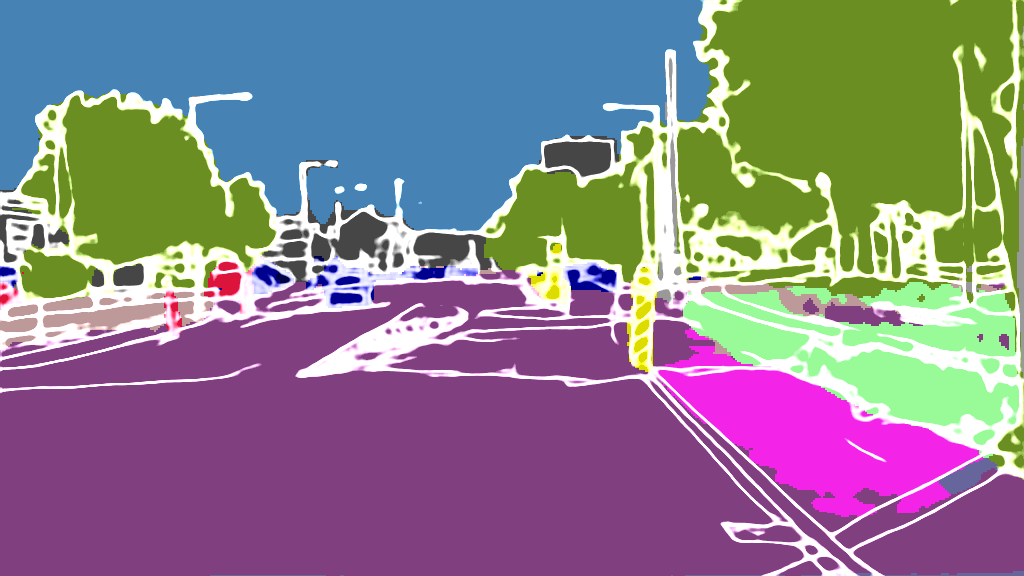
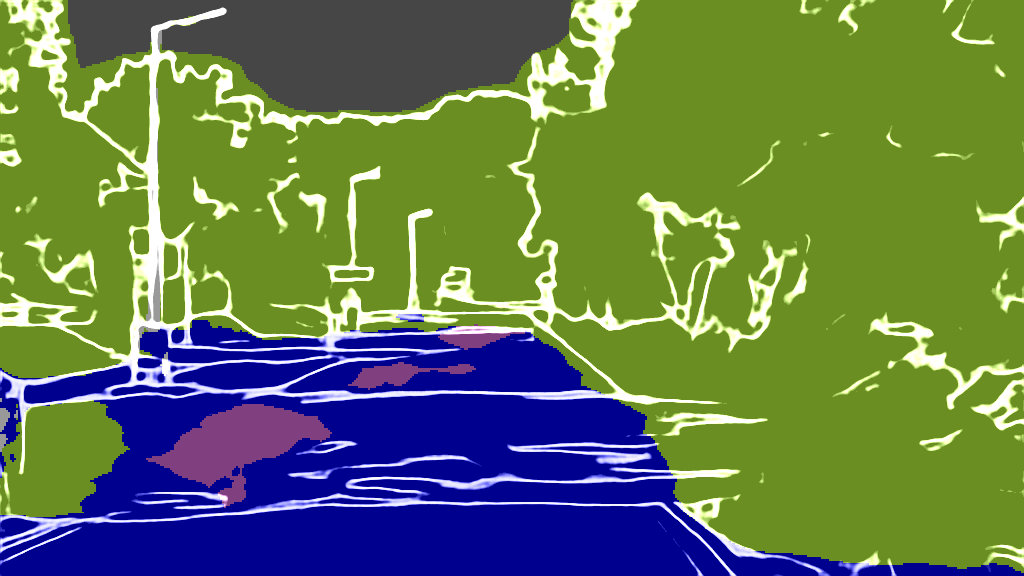
As extension of Figure 3 of the main paper, we show additional results for the 4 classes on the following pages. The examples were randomly selected according to the distributions shown in Figure 4 of the main paper and are sorted by the IoU.
CARLA
Input
Output
EPS map
IoU
0.831
0.519
0.464
0.422
0.369
0.335
0.293
0.238
Cityscapes
Input
Output
EPS map
IoU
0.949
0.714
0.646
0.595
0.549
0.500
0.457
0.399
FCAV
Input
Output
EPS map
IoU
0.943
0.506
0.446
0.397
0.365
0.340
0.310
0.260
KITTI
Input
Output
EPS map
IoU
0.834
0.561
0.510
0.483
0.447
0.414
0.372
0.319
Citation
@Article{Klein2021_eps,
author = {Klein, Jonathan and Pirk, Sören and Michels, Dominik L.},
title = {Domain Adaptation with Morphologic Segmentation},
journal = {Autonomous Driving: Perception, Prediction and Planning (ADP3) at IEEE Conference on Computer Vision and Pattern Recognition (CVPR)},
year = {2021},
month = {6}
}